
Evaluating submissions

We will evaluate submissions based on predictive validity, measured in the held-out test data by mean squared error loss for continuous outcomes and Brier loss for binary outcomes.
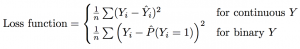
A leaderboard will rank submissions according to these criteria, using a set of held-out data. After the challenge closes, we will produce a finalized ranking of submissions based on a separate set of withheld true outcome data.
Each of the 6 outcomes will be evaluated and ranked independently – feel free to focus on predicting one outcome well!
What does this mean for you?
You should produce a submission that performs well out of sample. Mean squared error is a function of both bias and variance. A linear regression model with lots of covariates is an unbiased predictor, but it might overfit the data and produce predictions that are highly sensitive to the sample used for training. Computer scientists often refer to this problem as the challenge of distinguishing the signal from the noise; you want to pick up on the signal in the training data without picking up on the noise.
An overly simple model will fail to pick up on meaningful signal. An overly complex model will pick up too much noise. Somewhere in the middle is a perfect balance – you can help us find it!
Add your comment