
Job training
Policymakers often propose programs to retrain the workforce to be able to contribute in a 21st century economy.
We want to know: Do job skills programs utilized by caregivers yield collateral benefits for disadvantaged children?
Survey question
When children were about 15 years old, each child’s primary caregiver was asked the following question:

How we cleaned the data
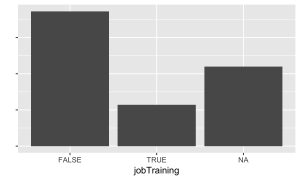
Those who did not participate in the age 15 interview, as well as those who refused (-1) or didn’t know (-2), were coded as NA. Those who responded “Yes” were coded 1, and those who responded “No” were coded 0.
Distribution in the training set
Scientific motivation
One way to raise people’s standard of living is to raise their human capital: the skills that promote productive participation in the labor force. Human capital investments are perhaps more important now than ever before given rapid globalization and computerization of the economy. Does participation in job training programs designed to build computer, language, or other skills improve the well-being of families? When caregivers participate in these programs, do children benefit indirectly?
Social scientists have long been interested in policy interventions to promote employment. This research has also been closely tied to the development of statistical methods for causal inference with observational data. In the 1970s, the National Supported Work Demonstration (NSW) randomly assigned some disadvantaged, non-employed workers to a job training program that included guaranteed employment for a short period of time. Others were randomly assigned to a control condition. The treatment led to measurable increases in earnings in subsequent years, suggesting that job training might be useful.
University of Chicago economist Robert LaLonde saw a new use for these data. Given that experimental results provided the “true” causal effect of job training on earnings, LaLonde wanted to know whether econometric techniques that statistically adjust for selection bias could recover this “true” effect in a non-experimental setting. In general, these statistical adjustments failed to recapture the “true” effect, and LaLonde’s 1986 paper became highly cited as evidence of the extreme difficulty of drawing causal inferences from observational data.
However, the story did not end there. About the same time, a pair of statisticians developed a new method for identifying causal effects: propensity score matching. In an enormously influential 1983 paper, Paul R. Rosenbaum (then of the University of Wisconsin) and Donald B. Rubin (then of the University of Chicago) showed that the average causal effect of a binary treatment on an outcome could be identified by matching treated units with untreated units who had similar probabilities of treatment given observed pre-treatment characteristics. The Rosenbaum and Rubin theorem held only in a sufficiently large sample and only when one estimated the propensity score correctly without omitting any important variables that might affect the treatment and directly affect the outcome. Despite these limitations, the key idea stuck: under certain assumptions, one can use observational data to try to re-create the type of data one would get in a randomized experiment where background characteristics no longer determine treatment assignment.
Empowered with propensity scores, two other statisticians reassessed LaLonde’s findings: could propensity score methods recover the experimental benchmark in the job training example? Raheev H. Dehejia (then of Columbia University) and Sadek Wahba (then of Morgan Stanley) found that they could. In two highly-cited papers (paper 1 and paper 2), they demonstrated that propensity score methods came much closer to recovering the experimental truth than the econometric approaches used by LaLonde.
The saga of job training and causal inference has continued to the present day. For instance, a 2002 paper by economists Jeffrey Smith (then of the University of Maryland) and Petra Todd (University of Pennsylvania) demonstrated that propensity score methods can be highly sensitive to researcher decisions. Since then, numerous statisticians and social scientists have used the job training example to demonstrate the usefulness of new matching methods: entropy balancing (Hainmueller 2012), genetic matching (Diamond and Sekhon 2013), and the covariate balancing propensity score (Imai and Ratkovic 2014), to name a few.
Be part of the next step
Clearly there is a lot of interest in human capital formation through job training. There is also interest in methods to infer causal effects from observational data. How does the Fragile Families Challenge fit in?
A slightly different treatment
The LaLonde (1986) paper and subsequent studies focused on an intensive job training program that connected non-employed individuals with jobs. The “treatment” variable which you will predict is much milder: participation in any classes to improve job skills, such as computer training or literacy classes. Respondents who enroll in these classes are not necessarily non-employed.
A robust propensity score model
One piece of conventional wisdom about propensity score methods is that one should be careful about selecting the pretreatment variables to include in the model, and one must model their relationship to the treatment variable appropriately. This is where you can help! Together we will build a highly robust community model for the probability of job training. This community model will take all of our best ideas and create one product on which we can all agree.
Specifying models before outcomes occur
A second piece of conventional wisdom of propensity score modeling is that it allows one to conduct all modeling and matching before even looking at the outcome variable. In our case, the ultimate outcome variables are not yet measured: we will examine the effect of caregiver job training on child outcomes in early adulthood. These outcomes will be measured several years from now, long after we lock in our community propensity score model.
Evaluating assumptions
All covariate-adjustment methods to draw causal inferences from observational data rely on the assumption of conditional ignorability (for more about this assumption, see our blog post about causal inference). Through targeted interviews with caregivers, we can provide suggestive evidence as to whether the conditional ignorability assumption holds.
You can help
Be a part of the next step in observational causal inference to evaluate the effect of job training programs. Apply to participate, build a model, and upload your contribution.
Add your comment