
At the Fragile Families Challenge Scientific Workshop, we devoted Thursday afternoon to breakout sessions where participants could work on specific projects that grew out of the Challenge. In this blog post we’d like to describe what happened in the breakout sessions, what we learned, and what is going to happen going forward.
Demo for the new Fragile Families metadata API and front-end (led by Maya Phillips and Alex Kindel)
Background: One of the things that we discovered during the Challenge is that much of the metadata about the Fragile Families study is stored in pdf files of codebooks that are designed to be read by people and are not designed to be machine-actionable (in the sense that they are easy to process with code). During the Challenge, one of the participants—Gregory Gundersen—converted some of the existing documentation into a metadata API. We loved his idea so much that the Board awarded him the Foundational Prize, and we decided to try to build on what he did by creating more metadata, a more fully featured API, and a web front-end for the API.
The API workshop began with a brief presentation about the interface proof-of-concept, its intended audience, and the different design decisions that we made along the way. Participants provided positive feedback, which gave us confidence in our design decisions. We determined that providing an API independent of the front-end enables the widest audience to make use of the data: both for more technical users invoking the API directly and for less technical users relying on the guided functionality of the front-end. The workshop proceeded to discuss some of the core functionality before doing a brief code walkthrough and demonstration of the front-end’s main features.

API discussion led by Maya Phillips and Alex Kindel
Discussing the different API functions helped to affirm the idea that complex queries could be created by chaining simple functions together (e.g. search variables, display variable). Therefore, we will build a few simple functions that are designed to fit together, rather than many specific functions for different use cases. For example, we plan to enable Boolean searches over the metadata fields, making it possible to quickly combine multiple searches. We also discussed the different ways queries can be made to the API: through a local copy, through Python or R libraries, or through web requests to a remote server. Providing a web server presents some trade-offs (e.g. between consistency guarantees and query speed), so we sought feedback on how users might think about this tradeoff. Given that the typical use case will involve only a couple of queries, we determined that consistency was more important than query speed, but we intend to provide a full CSV copy of the metadata in the event that researchers need to perform more intensive metadata analysis.
Participants were hesitant about the use of PHP to implement the API. Although we initially chose PHP for the backend in order to coordinate with local web development and maintenance resources at Princeton, the workshop attendees stressed the importance of a community-maintainable and open-source code base to which others could add useful features and make updates as the technologies advance. Moving forward, we intend to use a modern web stack to design the API and front-end for the revised metadata. It seems that this is critically important to those who will be using the API in the future, and is the most in line with the vision the team has for the project moving forward.
Workshop participants were generally enthusiastic about the demo version of the metadata browser front-end. The demo was designed to prototype interactions with the basic features of the API. The group had several feature requests for the web interface, primarily revolving around search:
- An option to save and aggregate multiple searches
- An option to copy and paste metadata (especially variable names) directly into code
- Logging user queries to provide the FFCWS community with additional information on which variables are being used
- Supplying data users with more information on possible responses, especially missing values
- Displaying additional information on variable groups in the search interface
- Naming queries to provide easy, commonly used shortcuts into the search interface
- Enabling search over all data fields, including tags and responses
We intend to implement several of these features before the public launch of the website.
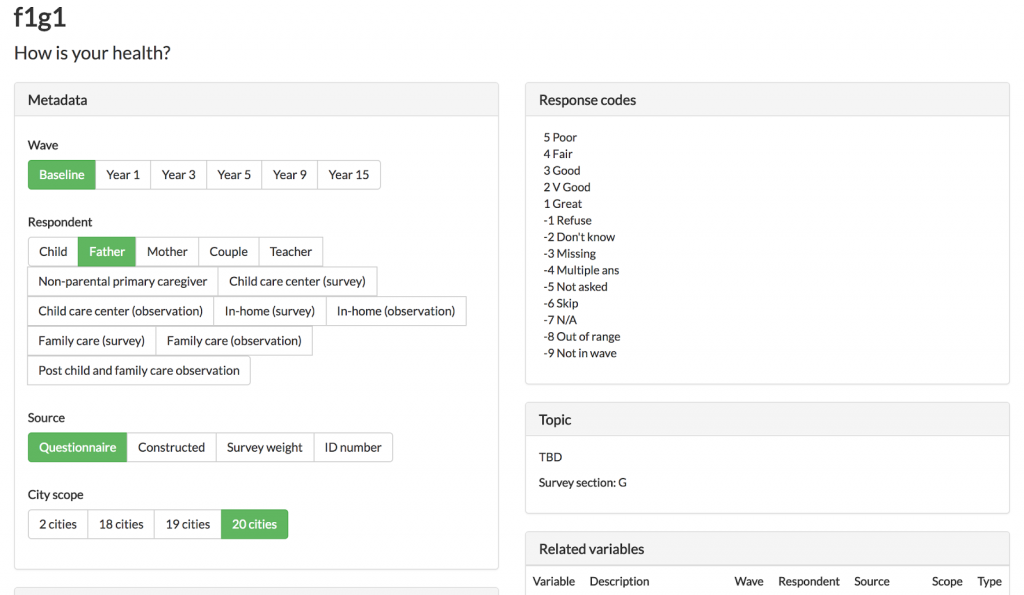
Figure 1. Variable browser search interface at the time of the workshop.
Figure 2. Variable metadata page at the time of the workshop.
Maya will continue to develop the back-end codebase by doing rigorous testing and adding features that will support the new features requested on the front-end. Alex and Maya will continue to work closely together as they build and integrate this architecture. In particular, a near-term goal is to identify and implement a relational schema for storing a canonical copy of the metadata; this database will serve the API, which in turn will serve the front-end and related software packages.
Testing and improving the Docker container that ensure reproducibility of the special issue of Socius (led by David Liu)
Background: One of the goals of the Fragile Families Challenge is to help promote a culture of open and reproducible research. Therefore, we required all participants in the Challenge to open source their submissions (code, predictions, and narrative explanations). This does not, however, ensure that it is easy for future researchers to reproduce the results of any of the Challenge submissions because we never checked that the code actually ran and future researchers may lack the appropriate dependencies to get the code to run. Therefore, for all the manuscripts in the special issue of Socius, we are ensuring reproducibility by re-running the code as part of the review process and packaging up the code and all the necessary dependencies in Docker containers that will make it easy for future researchers to download and run the code used in the papers in the special issue.
The reproducibility session began with a brief presentation of the project’s motivations and progress thus far. In addition to discussing the working of Docker, David Liu discussed patterns he has noticed in submitted code as well as a few suggested best practices for reproducibility.
It was particularly helpful to explain the background of Docker containers to the audience. For some, the explanation clarified the technical workings; the questions David received helped him better anticipate potential areas of confusion, which will be useful when releasing the containers to the public. A useful take away from the discussion on Docker is that the reproducibility work stands at the intersection of both research and software engineering; many of the principles and best practices of software engineering are relevant to conducting reproducible research. Examples include writing code that modular, assembling documentation during development, and testing the code as it is being written.
Next, David walked through a demo of how an actual submission was reproduced. This demo was particularly fruitful because the author of the submission (Tom Davidson) was in the audience and provided helpful commentary regarding his submission, which utilized neural networks. The demo illustrated how one would run Docker on Amazon Web Services and interact with the code. One of the undergraduates in attendance was able to follow the demo.
Overall, the session reinforced the community’s interest in viewing the open-sourced submissions. It was apparent that submitters were curious to see how others developed and implemented their models, beyond just the results themselves. In discussing and critiquing the code itself, we were able to better understand the author’s intentions and learn from their code development process. So reproducing and publicly publishing the code will satisfy a research need.
Looking ahead, David is reaching completion with five of the thirteen submissions written in Python and R, and he intends on completing the reproducibility work over the course of December and January. In the end, David will open source Docker containers for each of the journal’s models and include basic documentation regarding usage of the code. In addition, David will be able to provide recommendations for future social research software development to optimize code reproducibility. Finally, David can provide tips and guidelines for other journal editors on how to best reproduce journal submissions while also establishing a baseline for expected time commitment.

David Liu leading a discussion about reproducibility.
Assessing test-retest reliability of concept tags (led by Kristin Catena)
Background: One of the difficulties that participants encountered during the Challenge was selecting from the many, many survey questions that were available. Several participants asked us for a list of all questions related to education, for example. Such a list was not available. Therefore, we are now tagging all variables in the dataset with the social science concepts that they are attempting to measure.
As part of our new work on the FFCWS metadata infrastructure, we are adding a system of concept tags to the FFCWS variables so that users may more easily identify a list of variables related to a particular topic. For example, the concept tags would allow a data user to quickly identify all of the variables related to mental health or all the variables related to child support. It would also mark variables that are considered paradata – data that is about the survey administration but may not contain substantive information about the family (e.g., survey date, whether a particular participant completed a specific survey, etc.). Each variable will be assigned one or more concept tag(s) which will also be grouped into larger “umbrella” concepts. For example, mental health will be grouped under an umbrella of health while child support will be grouped under an umbrella of finances. When complete, the concept tags will be available through the metadata API and website (described above).
At the Fragile Families Challenge Scientific Workshop, we held a breakout session to test and discuss the concept tag system. Each participant was given a questionnaire to code into a provided list of tags. We also saved time afterwards to discuss the process and list of tags. In general, the participants reported that the concept tag list would be very helpful to data users and that they thought the list includes the concepts they would hope to search for. Several participants from data science backgrounds noted that they thought the umbrella concepts would be very helpful for orienting their work as they got started, but that the specific concept tags would be less helpful for them. Participants with more of a social science background, on the other hand, were interested in both the umbrella concepts and specific concept tags.
After the workshop, the participants’ tags were compared with those assigned by content experts from the FFCWS staff. 205 variables from four different FFCWS surveys were each coded by a member of the FFCWS staff and two different participants of the workshop breakout session. 95% of all variables coded had at least one tester who tagged the variable with the same concept as the FFCWS staff. Further, in 60% of all cases the FFCWS staff and both testers applied the same tag to the variable. Only 11 of the 205 variables had zero agreement between testers and FFCWS staff. We are now reviewing these results to strengthen and clarify the list of concept tags before completing the process of assigning tags to all remaining FFCWS variables.

Garrett Pace tagging variables with concept tags

Ian Lundberg tagging variables with concept tags

Steve McKay tagging variables with concept tags
Liberating question and answer texts from pdfs (led by Tom Hartshorne)
Background: As described above, one of the lessons from the Challenge was that we wanted to make more of the metadata available in machine-actionable formats. One example of this is the actual text of the survey questions. Right now, that information is currently in many different pdf files, which makes it cumbersome to search efficiently. Therefore, we want to make it easier for people to search and process the exact text of each question.
The goal of this project was to extract the exact text of the questionnaires out of PDF form and into a machine readable csv formatted file. This would allow future researchers to efficiently locate questions that have a certain keyword in either the question itself or the possible responses. It would also allow for our API and website (described above) to return the exact wording of the question associated with a particular variable.

Tom Hartshorne pitched the question text task to the group
Prior to the workshop, a procedure was iteratively developed to extract the text manually, but this proved time consuming. One of the goals going into the workshop was to use the collective expertise of the community to try and develop an automated way of scraping these PDF’s. During the workshop’s afternoon breakout session, Tom Hartshorne introduced the problem to a group of Challenge participants. Some members of the group worked to sharpen the manual process by going through it themselves and pointing out additional information stored in the questionnaires that could be useful to researchers. For example, Nicole Carnegie proposed adding the skip pattern associated with each answer choice. This is something that had come up in her Challenge experience, but had not been considered by the Fragile Families team prior to the Workshop. The manual process was very helpful for understanding the nuances of the questionnaires such as the string of periods between each answer choice, the formatting of “Circle all that apply” questions, and the location of the skip pattern information.

Question text working group led by Tom Hartshorne
While some of the group worked on the manual process, others worked towards a possible automation of the process. Cambria Naslund led this group of members, writing a Python script that parses an HTML version of the questionnaire to liberate the question text. This code strips the variables of their prefixes, then searches the questionnaire for a matching name. Once it finds a match, it grabs all the text following the first paragraph break up to the last paragraph break before the next question. It then cleans up this text, separating the answers from the question text using the long string of periods found between each answer choice. Each of these answers is stored in its own column, along with any skip patterns that may be associated with that answer choice. The output of this code will still require some manual cleaning, but it should greatly shorten the manual effort required by this task. We’ve now moved the software development to GitHub.
Conclusion
Overall, it was a very productive afternoon. We want to again thank everyone that participated.

Leah Gillion talking with Sara McLanahan

Coffee was available in abundance