
This guest blog post is written by Brian J. Goode, Discovery Analytics Center, Virginia Tech. The author was a winner of an Innovation Award.
Overview
One of the primary challenges of the Fragile Families Challenge (FFC) was to create a robust submission that is able to handle missing data. Of the nearly 44 million data points in the feature set, 55% of these values were either null, missing, or otherwise marked as incomplete. Discarding these data amounts to a substantial amount of information loss, and can potentially skew the data if there is any systematic reason as to why the nulls appear in the rows that they do. Imputing missing values preserves information content that was present, but introduces specific assumptions on the imputed values that may not always be verifiable. To the degree possible, the submission titled ‘bjgoode’ made use of the survey questionnaire to establish imputation rules based on the survey structure and familial proximity. As a result of this, the number of missing values decreased to 38% of the data set. The remaining missing data were filled in with the most frequent values. The implementation is straightforward, but tedious. The procedure is described below and resources are given at the bottom of this article. Results are given by the Fragile Families Challenge, but much work still needs to be done to evaluate the efficacy of the approach.
Procedure
There are four different approaches taken to impute values as part of this submission:
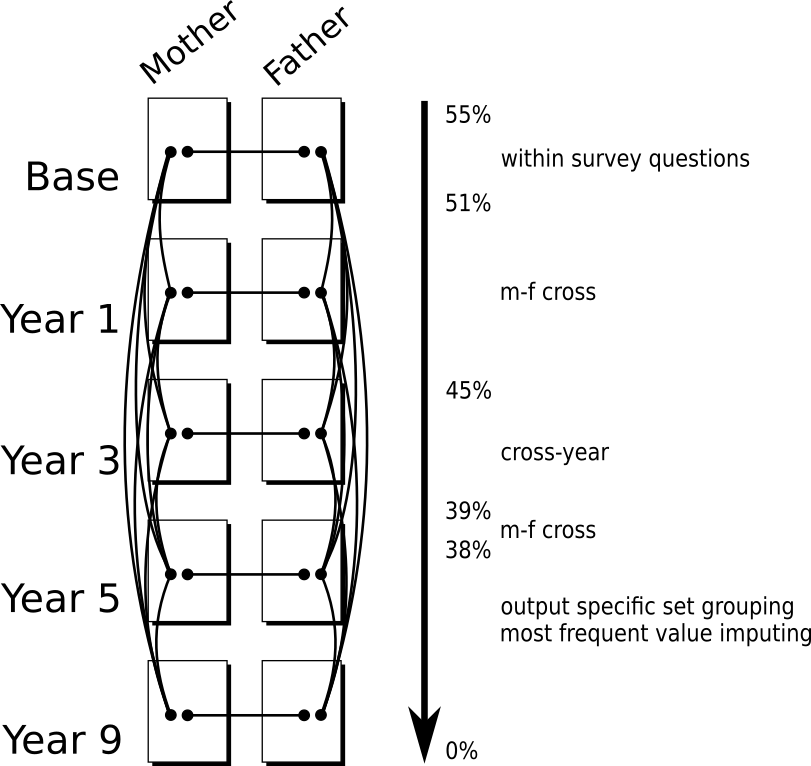
Figure 1. The various pathways for filling in missing data are shown in this diagram. The order of imputing values begins within each survey. Then Cross M-F imputing is completed. Finally, Cross year substitutions are made. The procedure reduced the number of missing values from 55% to 38% of the entire dataset.
1. Within Survey.
Some surveys, such as the mother/father baseline survey, have multiple pathways that an interview can follow depending on specific circumstances.
For example, there are whole blocks of questions that will be answered or not on the basis of whether or not the parents are romantically involved, partially romantically involved, and married. This means that by survey design, we can deduce that some questions are meant to have null values due to the pathway that was taken. For questions that are specific to the circumstance, there is little we can do. However, there were a number of repeated questions within these surveys that can be cross-linked. An example of this from the mother baseline survey (B5, B11, B22) is:
I’m going to read you some things that couples often do together. Tell me which ones you and [BABY’S FATHER] did during the last month you were together.
These questions were identified by text matching. When a value appeared in one path, it was transferred to the same question in the missing pathway. This reduced the number of missing values in the feature data from 55% to 51% missing.
2. Cross M-F.
One other reason for having missing values is that only one parent is actively involved in the study. For these cases, there is likely to be only one survey out of the mother, father, or primary caregiver surveys for a given survey wave.
In this case, we can impute data by finding related questions in each of these surveys with each wave. The value was transferred to each other matching survey question. The result of this is that some survey questions, instead of being answered strictly as mother, father, or primary caregiver are answered from the more general prototype of ‘supporting adult’ when viewed in isolation. If the data were used to form a complex structure of a specific parent, the non-trivial assumption is that the parents would have answered similarly. During each wave, the format and structure of the mother/father surveys were very similar within each section. Using this, it was faster and more accurate to do the mapping by hand by specifying question ranges. The mappings are provided in the Github repository listed in the Resources section. This procedure was performed twice. The first iteration reduced the output from the within survey mapping from 51% to 45% missing values. The second iteration reduce the output from the cross year mapping from 39% to 38% missing values.
3. Cross Year (wave).
Missing values also appeared to be more common during the later waves of the survey. This is not surprising given that it is a longitudinal survey and there are expected to be dropouts. To fill in these values, an assumption was made that it is more likely that a given mother/father survey response will remain persistent across time than not. As a cautionary note, this is a very strong assumption, especially for questions that have a smaller time scale. To avoid probing into specific questions, and assessing whether or not to use the latest known value or some other method for imputing, the mean value across available years was taken (note: all answers to survey questions were encoded with ordinal values).
The challenge here was to identify the related questions across years, because the same question was noted to be worded multiple different ways over multiple waves. This type of matching problem also has the characteristic that it is too cumbersome as a one-off instance to train an algorithm, yet also too tedious and error-prone for a human to match. The solution was to create a simple algorithm based on the NLTK Natural Language Processing Tookit in Python to identify similar questions by text. Having too few samples to properly train, a simple threshold was used to cluster questions into groups of related categories. However, thresholds have the ability to be both too conservative and too liberal in the error depending on the text and the type of changes that were made. Therefore, humans in the loop were included by having the script “propose” both correct and incorrect survey items within each cluster. A sample output is given here:

Figure 2. Example of output code for sets of related questions.
This process was much simpler and required little effort. However, without a gold standard for comparison, the exact accuracy of the algorithm cannot be stated with confidence. The code is available on the Github repository in the Resources section. Of the missing values, after the first cross M-F matching, the cross year matching reduced the number of missing values from 45% to 39%.
4. Output Specific.
The last major addition to the imputing strategy was to mimic the output measure being investigated as best as possible. All of the model outputs (outcomes) were derived from survey features and made public on the Fragile Families Blog (e.g., Material Hardship). For most of the outputs, except for GPA, there was a history of previous responses from surveys in previous waves. Therefore, for each of the outputs, a feature was made to correspond to the output in each survey where applicable. This was particularly helpful for features like Material Hardship that were formed from multiple survey questions and had the added effect of acting like an “OR”. Consequently, this is where the biggest performance gain was seen, but had little effect on the number of missing values.
After the steps were applied above, the remaining 38% of missing values were imputed with the most frequent value from each feature. All features exhibiting no entropy (all same values) were removed.
Results
The training and validation phase of the modelling phase showed that linear regression models were best for ordinal outputs: GPA, Grit, and Material Hardship. The remaining model outputs were best fit by logistic regressions. Although L1-regularization was implemented, for many of the outputs, the features were reduced to include only subjectively relevant features. For the case of Grit and Material Hardship, the features corresponding to the definition of the measure were picked. The feature combinations are too many to list here, but are shown in the code linked by the Resources section. Admittedly, this is not a fully automated procedure nor one grounded in theory, and is very likely to vary between researchers. However, I contend that this is evidence that we need to consider the larger model-system that includes both model design and resource constraints such as time. This will help us better understand how model development decisions impact the result and final implementation.
To fully understand the cost/benefit of the above imputation strategy one would need to conduct an ablation study and include other methods of imputation. Due to time constraints, that was not possible. But, from the design, matching the outputs appeared to show the greatest performance increase during the validation phase. As an approximate indicator of performance, the mean squared error (mse) and rank of each model using this data set is provided relative to the baseline here: FFC Results. Of note, the model is ranked 5th and 9th in the Material Hardship and Layoff outcomes respectively, but there were many better performing models. So, there is still an open question of the utility of this strategy in terms of overall performance, interpretability of imputing, and similarity of individual sample outputs.
What Next?
The work described above focuses on how data was imputed and selected to fill in missing values for the Fragile Families Challenge. However, more detailed analysis needs to be completed in order to reason about the strategy (or any strategy) with respect to the data, the challenge results, and the models themselves. This is currently ongoing and anticipated to be discussed in the forthcoming Socius submission as well as during the talk at the FFC Workshop on November 16th, 2017.
Author Details
Brian J. Goode, Discovery Analytics Center, Virginia Tech
I would like to Dichelle Dyson and Samantha Dorn for their help.
Resources
Github Repository: https://github.com/bjgoode/ffc-public